Thursday, 14 September
9月14日(木)
口頭発表 09:10 - 09:50 アバタ・バーチャルエージェント
座長:長谷川晶一(東京工業大学)
- 3D1-01
-
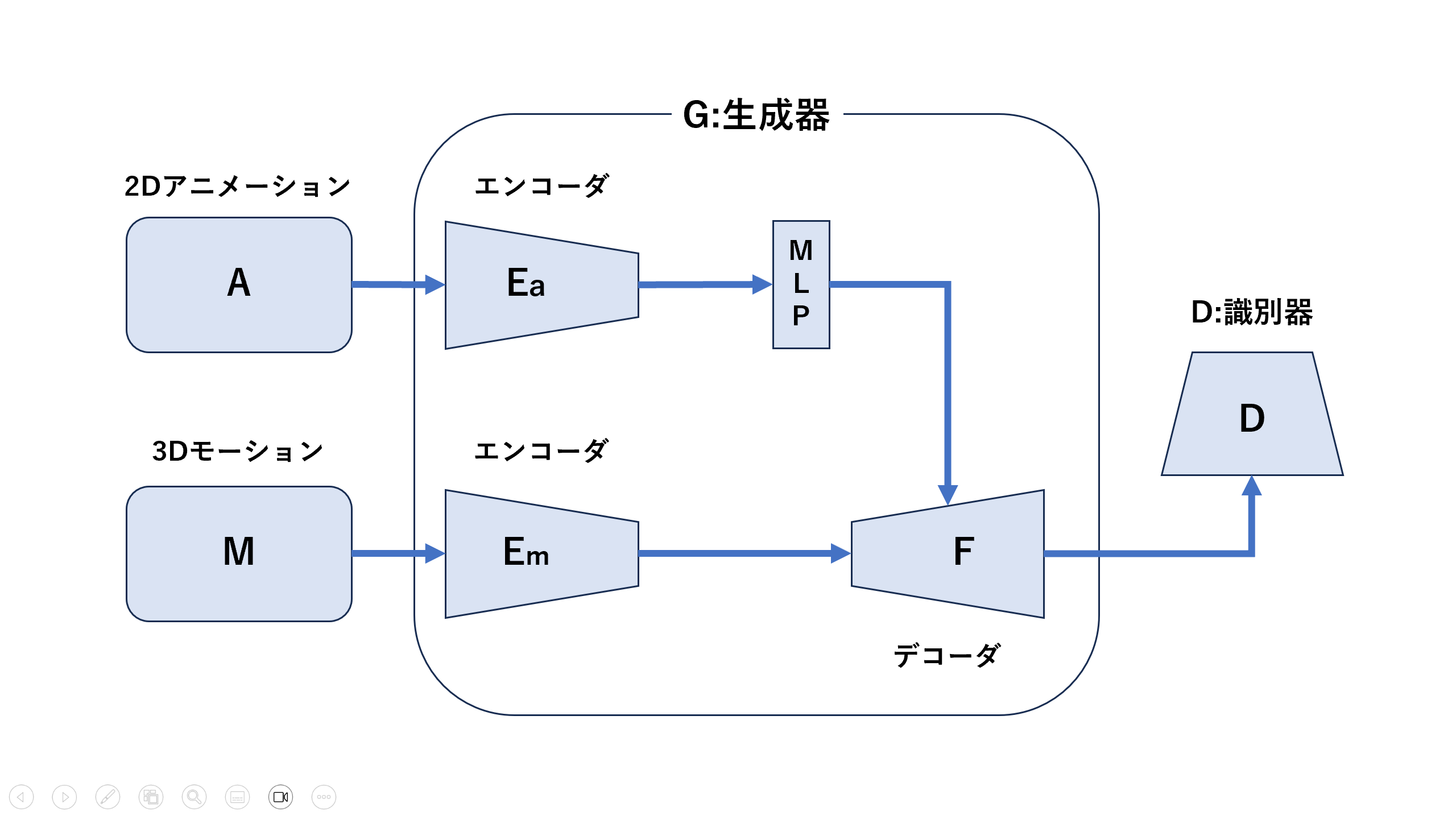
人間の3Dモーションデータの誇張表現生成ネットワークモデルの提案
〇飯田 航平(芝浦工業大学)、清水 創太(芝浦工業大学) - 本研究では,VR空間用に元の人間の動きを誇張表現した3Dアバターの動作を生成するネットワークモデルを提案する.ここで誇張とは,アニメーションなどでしばしばみられる,一見物理的にはおかしいにもかかわらず,逆にわかりやすい動作を表現することを意味する.誇張表現を適用することで人間にとって逆に違和感を感じにくい動作生成を目指す.
- 3D1-02
-
バーチャルライブにおけるアバタの動作を通じた観客同士のインタラクションが臨場感に与える影響
〇楊 光(電気通信大学)、櫻井 翔(電気通信大学)、松村 耕平(立命館大学)、岡藤 勇希(立命館大学) - 観客がバーチャルリアリティ(VR)空間上にアバタとして参加するバーチャルライブ(VL)は,場所や時間の制約を受けることなく音楽文化の流行や市場を広げる手段となっている。しかしVLでは他の観客の代替となるアバタには観客の動作が十分に反映されず、アバタの動作は画一的になっている。本稿では、VLが現実のライブのように感じることを臨場感と定義し,VLの臨場感に対する観客同士の動きのインタラクションの影響を調査する。

- 3D1-03
-
VRツイスターにおけるユーザ間の外見認識の相互不一致性が対人認知に及ぼす影響
〇後藤 拓海(電気通信大学)、櫻井 翔(電気通信大学)、野嶋 琢也(電気通信大学)、広田 光一(電気通信大学) - 実世界でもVR世界でも,知覚上の自他の身体に基づき互いの心理的・物理的関係性が変化する(身体化インタラクション).本稿では身体化インタラクションを拡張する方法論の探求を目的に,2人のユーザによるアバタを用いたVRツイスターにおいて,各ユーザのアバタの外見的性差に対する認識が必ずしも一致しない状況を生成した.また,この性差に対する認識がゲームプレイや対人認知,ユーザ間の関係性に及ぼす影響を調査した.

- 3D1-04
-
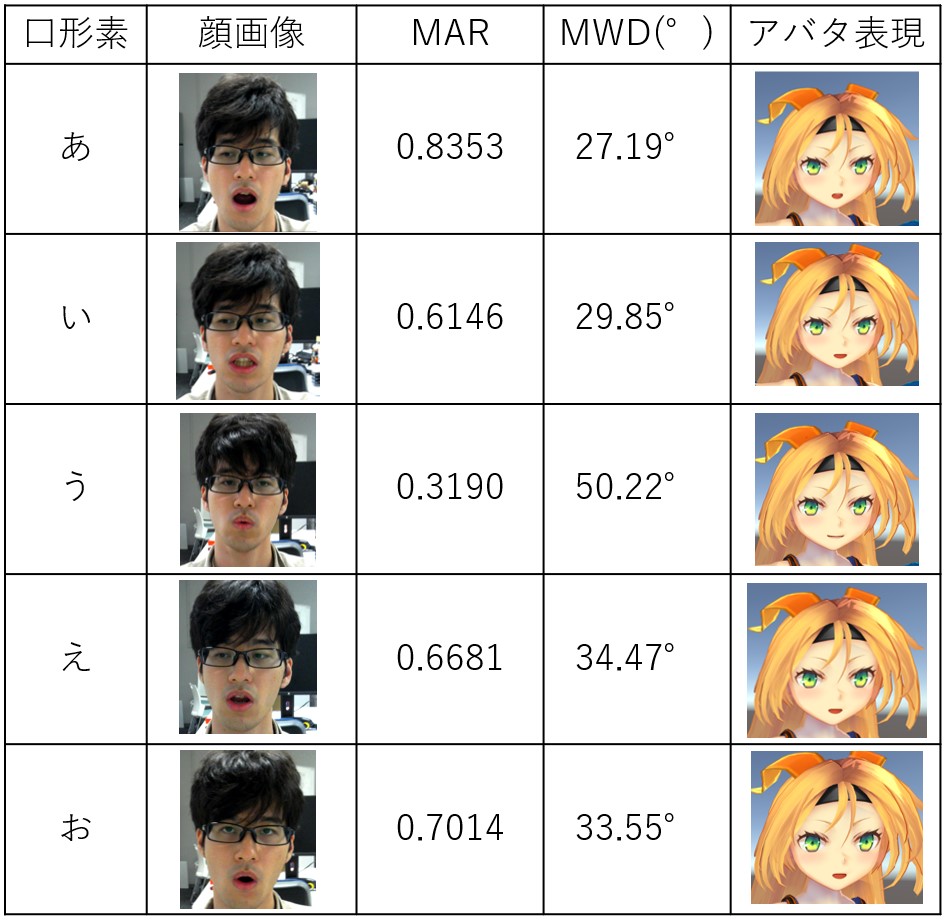
Media Pipeによる口形素についての抽出とアバタ表現への応用
〇戸田 壮駿(工学院大学)、田中 久弥(工学院大学) - メタバースでのアバタの表情表出を豊かにするために我々はWebカメラとMediaPipeの顔形状認識を用いて口形素の抽出方法を検討した。これまで音声情報に基づく口形素抽出はあったが画像に基づく方法はなかった。これにより発声または無発声でも母音の口形素が伝達できるようになった。我々は口形素情報をリアルタイムでアバタへ反映するシステムを開発し、従来の音声型口形素抽出法を基準として本手法の有効性を検証した。
- 3D1-05
-
バーチャルアバターの声量による歩行経路の制御
〇髙橋 宏太(豊橋技術科学大学大学院 工学研究科 情報・知能工学専攻)、北崎 充晃(豊橋技術科学大学大学院 工学研究科 情報・知能工学専攻) - 他者の声の音圧が対人距離に影響することが報告されている。本研究では、その知見に基づき、歩行する人の周囲に声の大きさが異なるアバターを配置し、暗黙的に歩行経路を制御する方法を開発した。アバターは二人一組で会話をしており、そのうち一組の音量を変化させて歩行経路を記録した。アバターに最も近づいた時の距離やスタート位置からゴール位置に到達するまでの歩行時間に関して評価を行った。

- 3D1-06
-
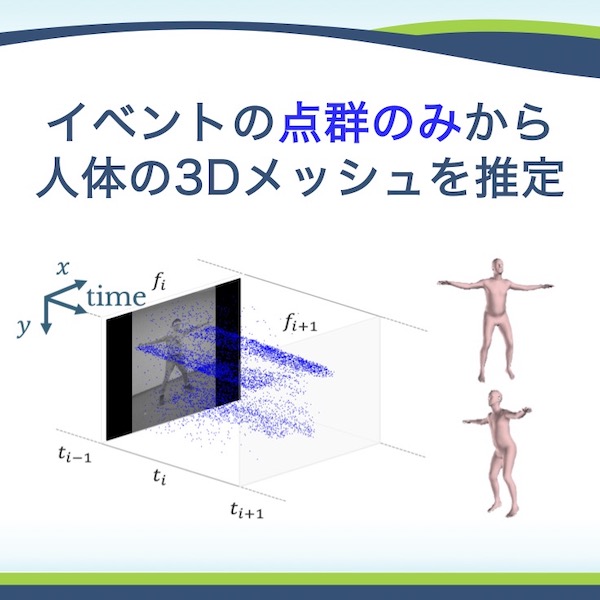
イベントデータのみを用いた三次元人物姿勢および形状推定
〇堀 涼介(慶應義塾大学)、五十川 麻理子(慶應義塾大学、JSTさきがけ)、三上 弾(工学院大学)、斎藤 英雄(慶應義塾大学) - 我々は,悪照明環境に頑健で,かつ省電力・省メモリな人物メッシュ復元手法の実現を目指し,イベントカメラで取得したイベントデータのみを入力とした人物メッシュ復元という新規タスクに取り組む.本稿では,イベントデータを時空間の三次元点群として扱い,人物メッシュを復元するフレームワークであるEvent Point Meshを提案する.既存のデータセットを用いてベースライン手法との定量および定性評価実験を行い,提案手法の有効性を確認した.
- 3D1-07
-
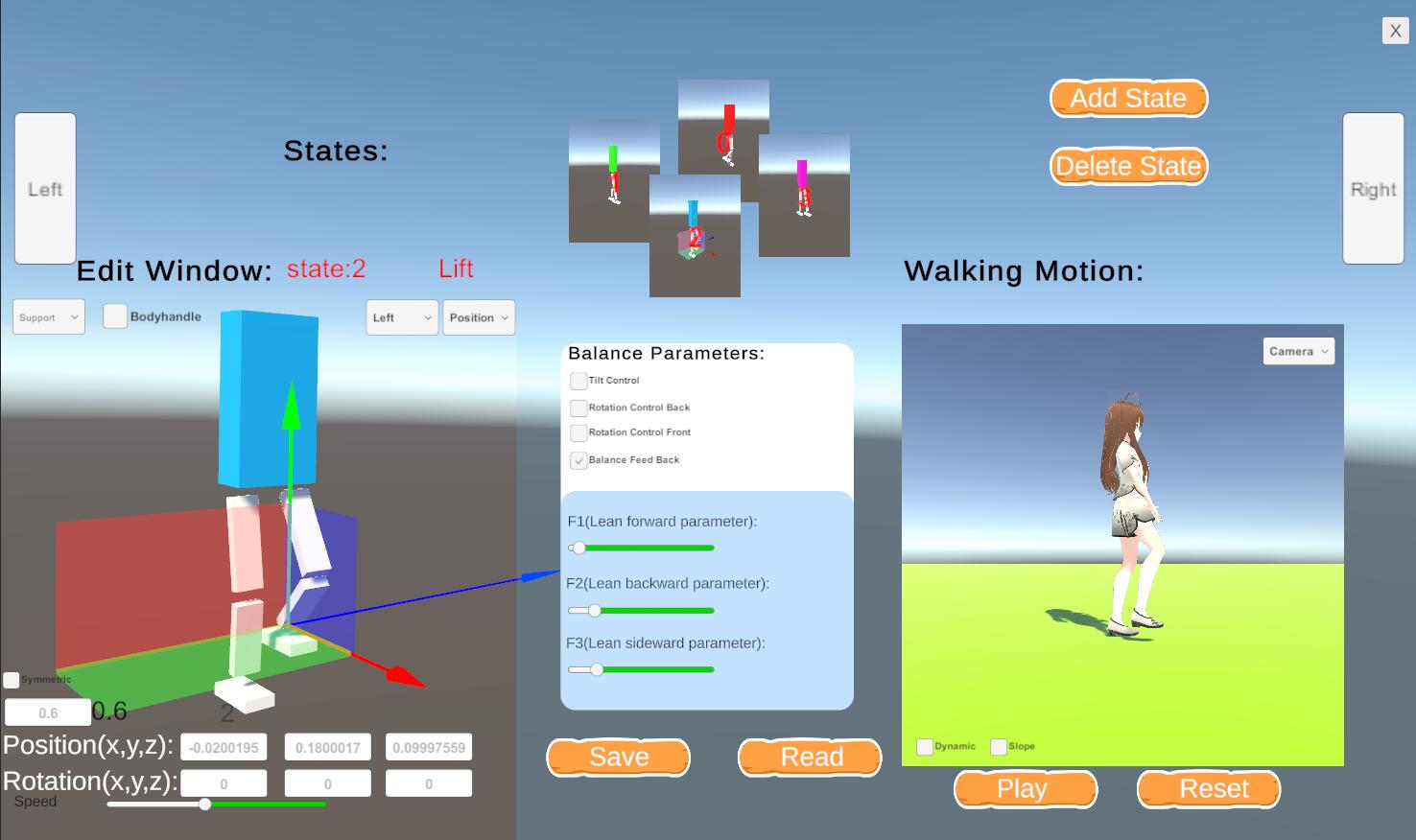
物理キャラクタの歩行スタイルとバランスの設計環境
〇藍 愷(東京工業大学) - リアルタイムで物理キャラクターの歩行スタイルを創作できるデザイン環境を提案した。このデザイン環境は歩行バランス制御の方法と動作編集するためのUIで構成される。ユーザーは、各歩行状態におけるキーフレームのポーズを3D視点で編集することができる。キーフレームには歩行周期において最も重要な4つの状態で構成される標準歩行スタイルを用意した。ユーザーはこの4つの状態に基づいて新しいスタイルを作成できる。
- 3D1-08
-
ソーシャルVRプラットフォームにおけるエージェントAPIの提案
〇倉井 龍太郎(クラスター株式会社)、平木 剛史(クラスター メタバース研究所) - 多数のユーザが空間を共有するソーシャルVRプラットフォーム上の自律的なエージェントを実装するには多様な情報が必要である。具体的には他ユーザとの距離、お互いの向き、アバターのポーズ、テキストや音声によるメッセージを認識し、それに応じた振る舞いが求められる。本稿では稼働中のソーシャルVRプラットフォームであるcluster上で上記のような情報を取得するAPIとAPIを利用したエージェントを提案する。

- 3D1-09
-
メタバース時代のアバターデザインの最適化
〇茂出木 謙太郎(株式会社キッズプレート、デジタルハリウッド大学、京都精華大学大学院) - 現在メタバース上ではアバターをホビーだけではなく、生活支援や職業としても活用しています。アバターはその外見等が操作する人の人格形成に影響を及ぼすことが研究で示されており、デザインの最適化は社会の大きな課題になると考えます。さらに、「なりたい自分になれる」だけでは、社会的活動を営む際には不十分です。ソーシャルなアバターデザイン方法を、キャラクターデザインの先駆者「マンガの制作手法」から学びます。
- 3D1-10
-
ロボットアバターを通じた長期的な社会活動が物語的自己に与える影響
〇畑田 裕二(東京大学)、武内 一晃(株式会社オリィ研究所)、加藤 寛聡(株式会社オリィ研究所)、山崎 洋一(神奈川工科大学)、鳴海 拓志(東京大学) - 本研究では,外出困難者がロボットアバター「OriHime」を遠隔操作して接客を行う「分身ロボットカフェ」にて,長期的に働いているパイロットが経験している物語的自己の変容に関してインタビュー調査を実施した。アバターは,ユーザーの身体特性を部分的に匿名化・編集することで,障害が前景化しない場を創出するとともに,現在や未来を規定していた条件付けを解除し,改めて未来に対する展望を開き直すことが示唆された.

- 3D1-11
-
分身ロボットカフェにおける複数ロボットアバターを用いた並列接客の長期的実証実験
〇川口 碧(慶應義塾大学)、Barbareschi Giulia(慶應義塾大学)、椎葉 嘉文(オリィ研究所)、加藤 寛聡(オリィ研究所)、脇坂 崇平(慶應義塾大学)、吉藤 健太朗(オリィ研究所)、南澤 孝太(慶應義塾大学) - 難病や重度障害などにより外出困難な人々が分身ロボットを通してカフェサービスを提供する分身ロボットカフェDAWN ver. βをフィールドとして、パイロットと呼ばれる操作者が、複数の分身ロボットを同時に操作可能な並列アバター環境を開発し、1ヶ月間におよぶ実証実験を行った。本稿では、実証実験の期間におけるパイロットらの内在的意識の変化や、普段の接客とは異なる複数の身体を活用したコミュニケーションの創発について報告する。

- 3D1-12
-
大規模言語モデルに基づく複数のキャラクタエージェントによるQ&Aシステムの提案
〇西尾 拓真(大阪芸術大学)、安藤 英由樹(大阪芸術大学)、宮下 敬宏(大阪芸術大学、国際電気通信基礎技術研究所)、篠澤 一彦(大阪芸術大学、国際電気通信基礎技術研究所、大阪教育大学)、萩田 紀博(大阪芸術大学、国際電気通信基礎技術研究所) - 大規模言語モデルを活用した対話型AIを利用する人が増えているが,そのまま活用するとユーザが本質的な理解にたどり着かない.一方で,複雑な問題に対して,様々な視点からの意見を聞くと自身の理解が深まるということもよく経験する.そこで,大規模言語モデルを利用した個性の異なるキャラクタエージェントを複数構築し,それらが議論を行うことでユーザに問題理解を促すコンテンツを自作・展示し,アンケート調査を行った.
